A Survey of Techniques for Maximizing LLM Performance

SNSで見かけたこのグラフ、詳細が気になってたので動画で公開されて嬉しい
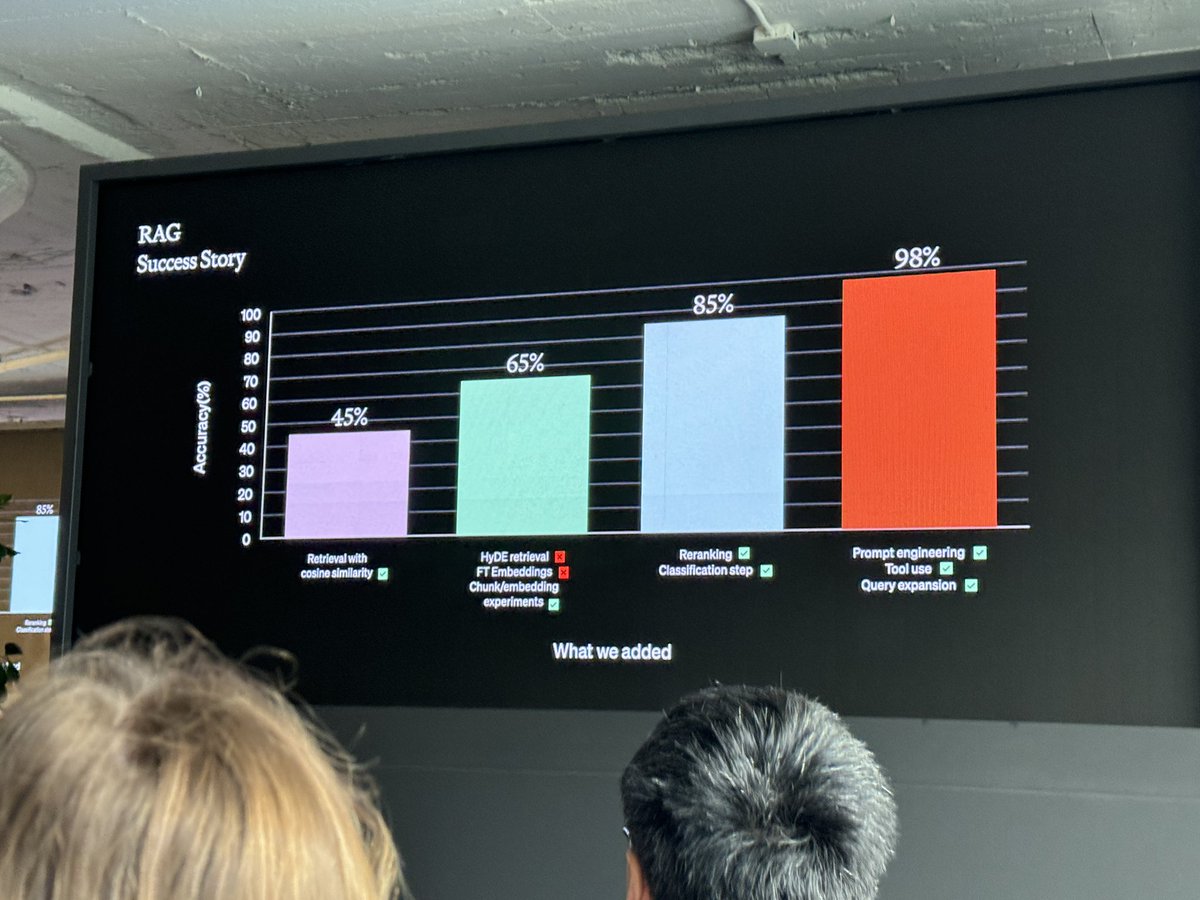
45%→65%
ベースラインは45%だった
まずHyDEを試した、これは今回のユースケースでは機能しなかった
埋め込みをファインチューニングすることも試した
これはアキュラシーの観点ではうまく機能したが、高コストで遅かったため採用できなかった
チャンクのサイズや区切り方を工夫
それによって20%改善して65%になった
まだ顧客に渡せるレベルではない
ここまでに20イテレーションしている
65%→85%
ルールの例: 最新のものを使う
大きな性能向上
分類
ドメインを分類して、それによって異なるメタデータを付与した
具体的には説明されてないが例えばサイボウズ的な文脈で言えば「これはスケジュールだな、参加者の情報を付与しよう」「これはスペースの会話だな、スレッドタイトルとスペースの名前を付与しよう」みたいなことだろう
85%→98%
再びプロンプトエンジニアリング
どのような質問で失敗しているのかを改めて観察
例えば明確な数値を必要とする質問に関して、ドキュメントから抽出するのをやめて、SQLを発行するツールを提供した
クエリ拡張
名前でイメージした作業と違った(検索対象の側にヒットしやすいデータを付与するのかと思った)
ユーザの入力を複数のクエリに分割して、それをパラレルで検索して、合成して返す
これはかなりユースケース依存の話だと思う
どこでもファインチューニングをしてない、これを強調したかった


Related Pages
- →precise_zero-shot_dense_retrieval_without_relevance_labels×仮説的文書埋め込み×Hypothetical Document Embeddings×hyde×instructgpt×contriever×埋め込みベクトル×blu3mo→

- →自分が興味がある分野の知識パッケージをllmに与える機能×chatgpt_plugins×OpenAI DevDay×assistants_api×retrieval-augmented_language_model×執筆は一次元化×人間のために書くよりLLMのために書く方が楽×知識を伝達するフォーマット×cybozu_days_2023-11-09×ユーザの関心に基づいた要約×意見の生成→

- →よくわからない気持ち×漠然とした不安感×恐怖は常に無知から生まれる×知識は恐怖の解毒剤×明確な不安感×問題は理想と現実のギャップ×悲観的な勘違い×強化学習_その1×s字発展×pscrapboxautotrans2023-03-25×英語話者国の競争優位×自分のscrapboxをchatgptにつないだ話勉強会×chatgpt_plugins×まだらな未来が拡大しない×世界がちぎれた後×未来はすでにまだらに存在している×未来から来ました×奥田_浩美×ビジョナリーリーダー×まだら×世間の常識×未来人×まだらな未来×定住する人×孤立して農耕をする村×茹でガエル×移動する人×ベーシックインカム×worldcoin×観光立国×優秀な若者×人攫い×詐欺師×面白い×アーリーアダプター集団の形成×人的ネットワーク×移動×アーリーアダプター×ムーブメントはフォロワーが作る×アーリーアダプター濃縮効果×観測困難×世界のちぎれ×snsはなぜ栄枯盛衰するのか×弱い紐帯×津波てんでんこ×一人でも逃げろ×指示待ち×話を聞かない人×動かない人×津波×どこに逃げればよいか×観測範囲を広く×移動先が決まる前に移動を始めなければならない×津波が来る方に賭ける×パスカルの賭け×バーベル戦略×反脆弱×llm無職×人生を悩む×人間のために書くよりLLMのために書く方が楽×自分が興味がある分野の知識パッケージをllmに与える機能×OpenAI DevDay×assistants_api×執筆は一次元化×知識の投網×領域を開拓して旗を立てる×ノウアスフィアの開墾×需要の規模によってgpuの使用効率に差が生じる×垂直統合×llm時代のグループウェアの適切な抽象レベル×ビジネスモデル探索×ai失業をfactorioで説明する×aiに仕事を奪われる×0/1の思考×システムの理解×factorio×解雇規制×人事異動×仕事に役立つ新・必修科目「情報ⅰ」×プログラミング教育の必修化×世界とのインターフェース×情報を抽出伝搬する×要約は曖昧概念×正常性バイアス→

"Engineer's way of creating knowledge" the English version of my book is now available on [Engineer's way of creating knowledge]

(C)NISHIO Hirokazu / Converted from [Scrapbox] at [Edit]