Lost in the Middle: How Language Models Use Long Contexts
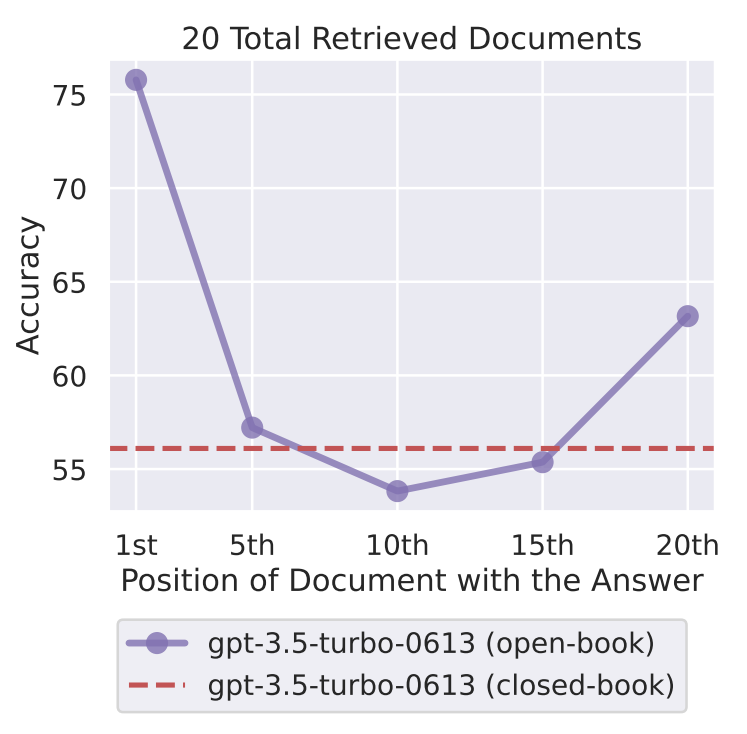
>While recent language models have the ability to take long contexts as input, relatively little is known about how well the language models use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
>@ImAI_Eruel: トークン長の長さは話題になるところですが,実際にLLMに入力する長いプロンプト(コンテキスト)では,先頭か最後の方に重要な情報が含めたほうがいいという研究
>実験でも,位置の違いで相当な精度差
>使い慣れた人は直感的に把握してそうな知見が改めて研究でしっかり示された感
>
"Engineer's way of creating knowledge" the English version of my book is now available on [Engineer's way of creating knowledge]

(C)NISHIO Hirokazu / Converted from [Scrapbox] at [Edit]